Leveraging dbt model versions to enhance trust and reliability
![]() 10 minute read
10 minute read
10 July 2024
In the first post of this series on dbt Mesh, we explored how and why to implement model contracts in dbt. These contracts help maintain data integrity and trust across your data ecosystem. But what happens when you need to make a change to that contract?
This is where model versioning, a feature of dbt Mesh, comes into play. Model versioning simplifies managing breaking changes and facilitates smooth data product transitions, ensuring that your data remains reliable and trustworthy even as it evolves.
Understanding Model Versions
In dbt, a model is a table or view within your database, created from a SQL select statement or from Python returning a dataframe. These models are the building blocks of your transformation pipeline, providing the output for downstream teams and evolving over time. Changes to a model’s structure or logic can potentially disrupt downstream systems and processes that rely on that model. This is where dbt’s model versioning becomes crucial.
Model versioning allows you to create and manage multiple versions of the same model within your dbt project. This enables you to publish changes and test them before promoting them as the new “latest” version, giving downstream consumers time to adjust accordingly.
Why Version Models?
Being on the downstream side of a breaking change can be stressful. Sometimes the impacts of the change are not well known ahead of time.
In a data mesh architecture, where data ownership and management are decentralised across different domains, the need for versioning models becomes even more critical. Here are some key benefits of using model versions in a data mesh implementation:
- Smooth Transitions:
Model versions allow for gradual transitions when introducing breaking changes to data products. Domain teams can allow early access to the new version, allowing time to prepare for the cutover. - Empowered Domain Ownership:
By versioning models, domain teams have full control over the evolution of their data products. They can make changes, introduce new versions, and manage deprecation cycles. - Improved Governance:
Model versions enable better data governance by providing a clear audit trail of changes and a structured approach to managing data product lifecycles. This fosters trust and reliability across the entire data ecosystem.
This post is focusing on the technical implementation from within dbt. For the best overall business outcome, these features need to be combined with strong organisational data governance and change management practices.
Implementing Model Versions
Let’s consider an example where the “Suppliers” team needs to introduce a breaking change. Changing their `dim_supplier` model by removing the `address ` column.
1. Create a New Version File:
The team creates a new file named ‘dim_supplier_v2.sql’ containing the updated model definition without the ‘address’ column.
2. Define Model Versions in YAML:
In the ‘schema.yml’ file, the team declares ‘dim_supplier’ as a versioned model and specifies the differences between versions:
models:
- name: dim_supplier
latest_version: 1
config:
contract:
enforced: true
columns:
- name: supplier_sk
data_type: varchar
- name: supplier_key
data_type: number
- name: supplier_name
data_type: varchar
- name: address
data_type: varchar
versions:
- v: 1 # Version 1 (current latest)
# No additional configuration needed
- v: 2 # Version 2 (new version)
columns:
- include: all
exclude: [address] # Exclude address column
3. Deploy code:
The team goes through the usual processes to release the new model. Usually this involves testing, documentation, pull request, continuous integration test, code review then merge.
4. Communicate and Migrate:
The team communicates the change to other domains consuming the `dim_supplier` model. Other teams can connect to it as a ‘pre-release’ version (`dim_supplier`, `v=2`). At this stage, communicate and plan on timeframes for cutover to v2 as the ‘latest’ version. There is also an option to pin to v1 at this point, so when the default changes there is no impact.
v1 is still the latest and default version.
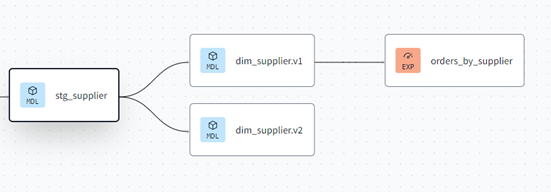
View of lineage diagram with the two versions shown. The exposure is referring to ‘dim_supplier’ so defaults to v1.
5. Promote to Latest:
When ready, the team updates the ‘latest_version’ in the YAML file to ‘2’. Promoting ‘dim_supplier_v2’ to be the latest version for their data product.
models:
- name: dim_supplier
latest_version: 2
At this point, the original dim_supplier.sql needs to be renamed to dim_supplier_v1.sql if you have not already done so.
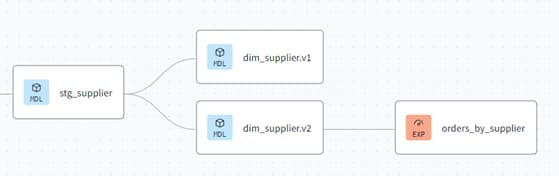
Lineage of the exposure automatically pointing to v2 after the change.
6. Plan to deprecate:
Working with the other domains, the team makes a plan for when to deprecate the original version. During this period, downstream domains can continue referencing the previous version (`dim_supplier`, `v=1`) until they migrate their queries and processes to the new version (`dim_supplier`, `v=2`).
7. Deprecate Old Version:
After the migration window, the team can deprecate the old version (`v=1`). dbt Explorer provides a visual to help know if there are still downstream users of the v1 model.
By following this process, the “Suppliers” domain team can introduce breaking changes to their data product while minimising disruptions to other domains and maintaining a reliable data ecosystem.
Conclusion
Leveraging dbt’s model versioning capabilities, organisations implementing a data mesh architecture can effectively manage the evolution of their data products while minimising disruptions and maintaining a reliable data ecosystem. This feature empowers domain teams to introduce changes at their own pace, facilitates smooth transitions, and fosters better governance and trust across the entire data landscape.
In the next part of this series, we’ll explore how dbt’s cross-project referencing feature complements model versioning, enabling seamless integration and consumption of data products across different dbt projects.
About the Author
Meagan is a Principal Consultant with Altis Consulting based in Sydney. She is a passionate about elevating data team practices to increase trust, reliability, and business value. A dbt Certified Developer and regular dbtCloud trainer, Meagan has implemented dbt across numerous clients.
Connect with Meagan via LinkedIn or get in touch meaganp@altis.com.au
Do you want to find out more about dbt Mesh can enhance your data projects?
Connect with Altis today to discuss how the dbt features can benefit your organisation.
Related insights
Share
Other insights





Contact us via the form on our website or connect with us on LinkedIn to explore the best solution for your business.