Reports of the star schema’s death are greatly exaggerated – Part 1
![]() 11 minute read
11 minute read
1 June 2023
And then there was Dimensional Modelling
Beginning in the 1980s and gaining speed after The Data Warehouse Toolkit’s 1996 release, Dimensional Modelling has enabled organisations to better understand their activities and become more data-driven.
But new innovations in technology mean we can (and should!) re-consider our ways of working. A shift to the cloud in the past ten years has enabled cheaper storage and scalable, on-demand compute, while columnar file formats have helped to optimise Big Data workloads with better compression and more efficient reads. These and other innovations have led some data professionals to eschew Dimensional Modelling (and the synonymous Star Schema), labelling it a dinosaur from a bygone era. But is there a place for Dimensional Modelling in the modern data landscape?

Figure 1: Steve Jobs makes light of his own health concerns in 2008 with a reference to Mark Twain’s famous (and misquoted!) 1897 aphorism. I can imagine many thousands of well-functioning Star Schemas decrying similar reports of their demise.
To answer that, we’ll need to understand exactly what Dimensional Modelling is as well as its purpose. And, If the Star Schema is dead, who is holding the murder weapon? What’s the alternative?
In this two-part blog series, I’ll examine both questions. In this, Part 1, let’s move past assumptions about what Dimensional Modelling is to find out why it exists and why it’s been around for so long in an ever-changing industry.
In Part 2, coming soon, I’ll talk to The Kimball Method and alternative data modelling techniques – or lack thereof – and whether they mix with Dimensional Modelling.
Best by test
The Kimball group – a group of authors who wrote about and practised Dimensional Modelling extensively from the 1980s until 2015 – are widely credited with popularising the Star Schema. They created their own methodology, called the Kimball Method, and described it in The Data Warehouse Toolkit (1996, with revisions in 2009 and 2013) – this method is what’s commonly referred to as Dimensional Modelling (especially when the ‘D’ and ‘M’ are capitalised!).
The Star Schema was a response to the normalised entity-relationship models used in operational systems’ databases (typically third normal form, or 3NF). Specifically, the Star Schema was a response to how poorly normalised models were at answering business users’ analytical questions, both in terms of query performance and ease of use.
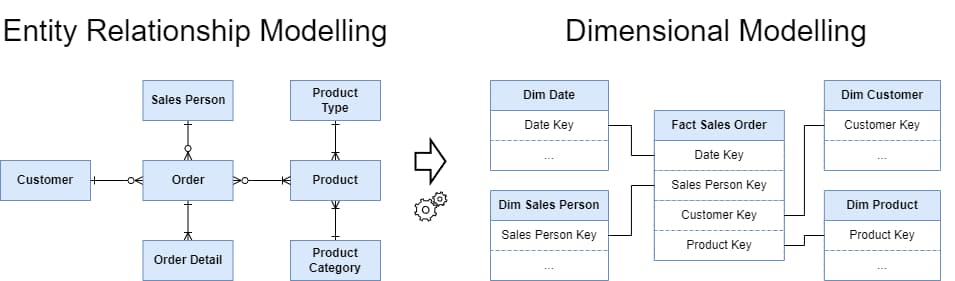
Figure 2: Entity-Relationship Modelling is best used in Online Transaction Processing (OLTP) systems, while Dimensional Models are intended to support reporting and analytics solutions.
In a Star Schema, an organisation’s transaction data (real-world events like sales, registrations, customer inquiries, and shipments) are retained in Fact Tables, similar to transactional tables in normalised modelling. But the context surrounding these events is de-normalised, based on a logical grouping of attributes – so Product Name is grouped with Product Category, and Product Type into a single entity called the Product Dimension.
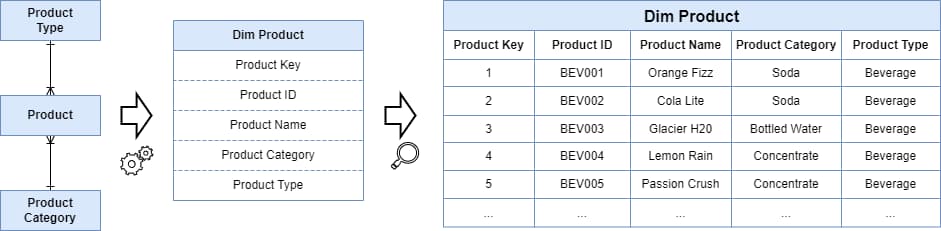
Figure 3: In Dimensional Modelling, multiple normalised entities are reduced to a single de-normalised dimension.
Normalised data structures provide advantages for operational systems such as efficient updates, inserts, and retrieval for single records (since only the minimum number of rows need to be modified to effect these changes), and efficient storage (since there are no unnecessarily repeated pieces of information).
These same features make normalised data models poor candidates for analytics, where reading many rows at a time is the norm. Rather than scrutinising a single record as is often done in an operational setting (“Customer X ordered product Y on Z date – show me the shipping status.”), we want to retrieve many records at a time, filter them by certain criteria, then summarise them by other criteria, and aggregate the result (“What were our most popular product categories in the last three quarters, and how has that changed in the past five years?”). Since analytical queries typically consider data over several prior periods, inserts and updates in real-time often aren’t required, so processing can be completed in large batches after business hours.
Structuring data in this way helps Dimensional Modelling to achieve two primary goals:
- Ease of use; and
- Fast query performance
These goals form the bulk of Dimensional Modelling’s raison d’etre, so let’s examine each more closely.
Ease of use
Ease of use is a timeless requirement for structuring data, so what contributes to data that’s easy to use? Firstly, it’s framed in the business’ language, not the language of the source system’s back-end database. Secondly, the joins between dimensions and facts are typically simple and far fewer in number than for a normalised approach.
Dimension tables, used for slicing and dicing (and for aggregating up and down attribute hierarchies), are easily recognisable as the nouns of a business (or the master data entities if that makes more sense) – Customer, Product, Staff, Storeroom, etc. The nouns are clustered around verbs – things the business does – take orders, manufacture products, answer support requests, etc. The verbs, of course, are the Fact Tables.
By doing away with database lingo (“tbl_cust_att.add_h_2” becomes “[Dim Customer].[Alternate Home Address]”) and removing the myriad of joins created by normalisation, dimensionally modelled data makes intuitive sense to business users, who recognise the dimension and fact tables as innate parts of the business’ operation.
To communicate a data model at a high level (say, to an executive group), Kimball recommends relating the nouns to the verbs with a table (a Bus Matrix, in Kimball terms), similar to a Conceptual Data Model. Presenting the data model in this simple table format allows stakeholders to imagine the analytical capabilities before the model’s implementation.
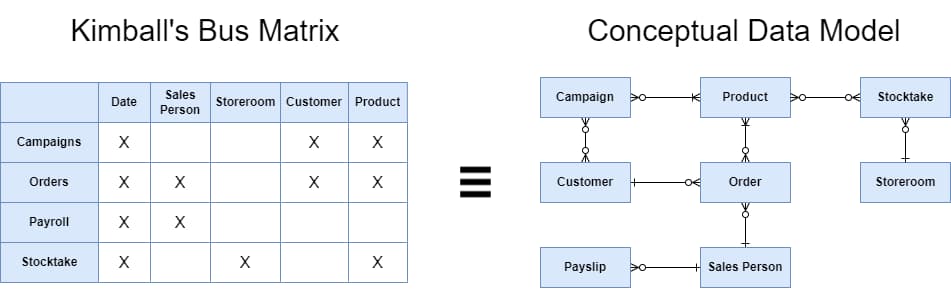
Figure 4: A Kimball Bus Matrix compared with a Conceptual Data Model. The Bus Matrix categorises business activities (rows) and business master data (columns), showing at a glance which processes utilise which master data.
Fast query performance
Query performance is typically dependent on two factors: the throughput and latency at which data can be accessed (e.g., from disk or from stored memory), and how many operations (e.g., joins or computations) are performed.
Where the performance of Dimensional Modelling really shines over normalisation is a significant reduction in the number of join operations, mainly possible because the dimension tables have been denormalised to include repeating hierarchical attributes (remember, Product Name, Product Category, and Product Type all go in the same dimension table!) as well as any other relevant attributes that “belong” to the dimension in question. Denormalisation comes at the cost of additional storage space and – potentially – fewer rows stored in memory or read from disk at one time. However, disk space (in the twenty-first century) is cheap, and modern compression techniques lessen the burden of repeating values (like our hierarchy attributes).
Throughout the past 30 years, many technological methods of improving query performance have been employed. A few, where a “traditional” database isn’t used include OLAP cubes (pre-aggregation of data along all possible dimension intersections), Massively Parallel Processing (MPP) systems (dividing complex queries amongst many nodes that run in parallel with each one solving a small piece of the puzzle), and In-Memory OLAP systems (which store and access datasets within fast system memory instead of from slow disks, and rely on compression to accommodate larger datasets).
The things these technological systems have in common is that they are all compatible with – not hostile towards – dimensional modelling and organisations would (and often do!) benefit from first dimensionally modelling their data before optimising the delivery technology.
It ain’t what you don’t know that gets you into trouble…
As a consultant, I hear some strange convictions about Dimensional Modelling which sometimes leaves me scratching my head as to where these notions came from. Let’s emphasise some salient points about Dimensional Modelling and clear up misconceptions in the process.
- Dimensional Modelling is about delivering data to end users. Sometimes that user is a report consumer, other times an analyst, and other times still a data engineer. Thus, Dimensional Modelling is only concerned with the Presentation layer – the area of a Data Platform where the user sees and can access data. Data does not have to be persisted to database tables, files, or anywhere else to be considered dimensionally modelled. Any kind of semantic layer over the top of tables, files, API queries, or other services that provide data can form the Dimensional Model.
- Dimensional Modelling presents an enterprise view of data and thus can form an Enterprise Data Warehouse (EDW). Although the term EDW is often used to describe a pre-dimensional, integrated (and sometimes normalised) layer of data such in Bill Inmon’s Corporate Information Factory (CIF) or the Data Vault approach which succeeded it, it applies equally to Dimensional Modelling.
- Most other approaches to analytical data modelling are not actually other approaches at all, as they use Dimensional Modelling as a part of their recommended solution! For instance, CIF and Data Vault both recommend delivering data to users via Star Schemas, and even “no modelling” approaches like One Big Table (OBT) may leverage Dimensional Models as a part of their (pre-OBT) workflow. Instead, these approaches differ from Dimensional Modelling by their overall architectural approach to data warehousing – more on that in Part 2 of this blog.
And that’s not all…
We’ve seen that Dimensional Modelling’s ability to present data to stakeholders in a way that accurately represents the business’ operations while facilitating ease of use and performance is the reason it has persisted for more than 30 years and remains the most popular option for modelling Data Platform presentation areas today.
But is a Star Schema the same as Dimensional Modelling? Are they both the same as the “Kimball Method”? Do the alternative approaches spell the death of Dimensional Modelling? Armed with what we now know, those questions and more will be answered in Part 2 of this blog, coming soon.
For more than 25 years Altis has used Dimensional Modelling to deliver best-practice Data Platforms for our clients. To learn more about our training or consulting services, we invite you to connect.
Written by
Principal Consultant
Altis Consulting
Related insights
Share
Other insights





Contact us via the form on our website or connect with us on LinkedIn to explore the best solution for your business.