

Richard Roose, NSW Delivery Lead shares his views on where Snowflake fits into a Data and Analytics architecture.
Whilst RDBMS’s have long been used for traditional transactional workloads (OLTP), the focus of this discussion is on their use for Data & Analytics workloads (OLAP).
In a world of on-premise vs. on-premise cloud vs. native cloud vs. hybrid vs. DWaaS, it can often be confusing what’s included in a particular offering and what’s not. There are also a number of “hidden or masked” costs that show up on separate bills making TCO comparisons even more difficult.
So, how to break all this complexity down?
The table below is a good starting point/checklist as you start to compare the various offerings out there:

As you can see, it’s the “hidden or masked” costs which can be the “gotcha” in overall TCO – as the legal eagles often say,“buyer beware”.
So, cost is one thing and from the table above, you can see that Snowflake offers a transparent way of managing those – but what else?
Traditional RDBMS’s have their limitations when it comes to Data & Analytics…
It’s hard to know where to start but the developers at Snowflake sat down a few years ago and “re-imagined” what an enterprise/big data warehouse/data lake/data hub in the cloud should look like. To do that, they looked at why every architecture prior had its shortcomings and then set about addressing that with a new architecture built not only specifically for the cloud but also particularly for Data & Analytics workloads.
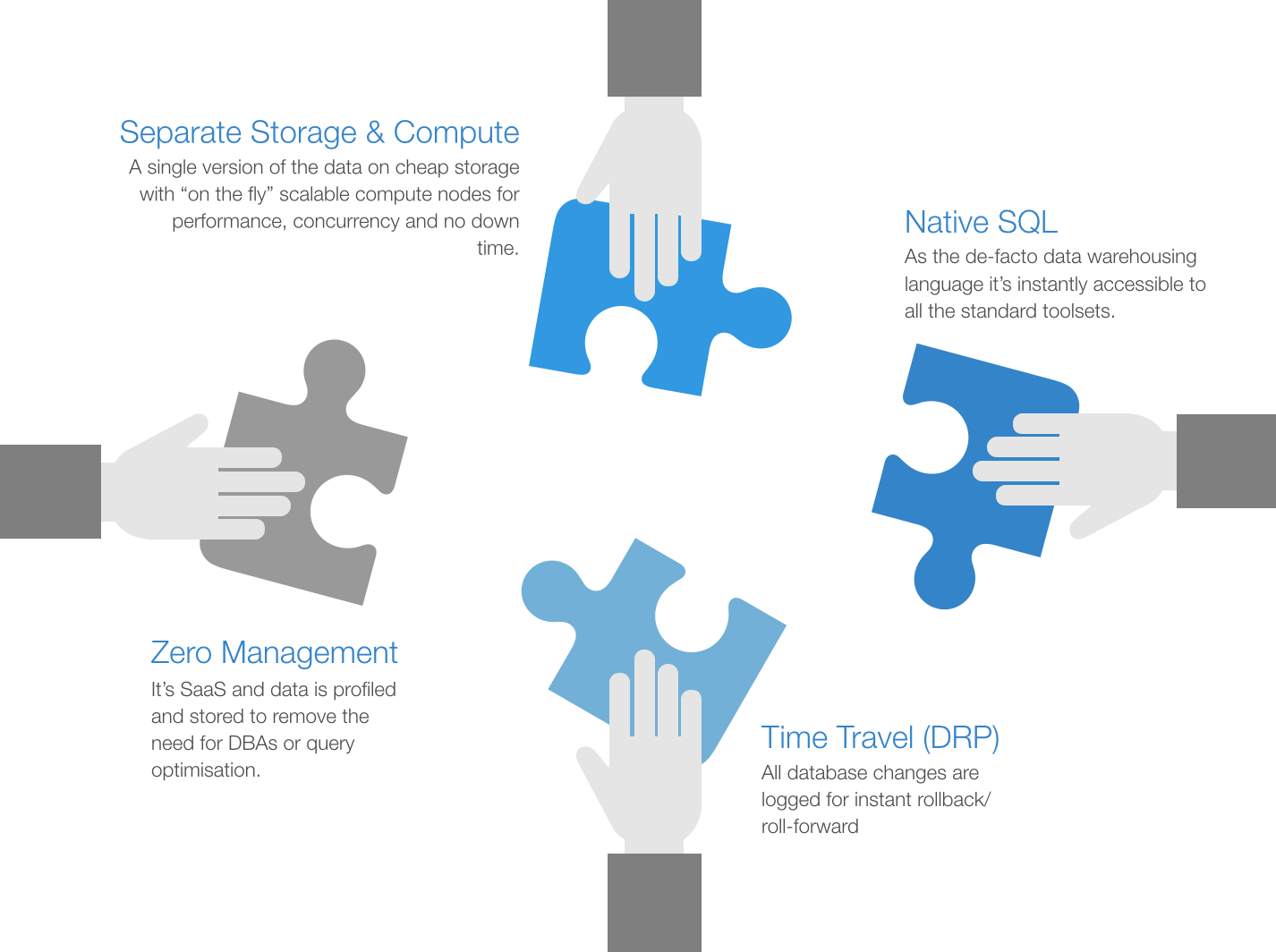
Here are some of the key elements of Snowflake’sarchitecture that give them the tag of “disruptor”.

Separate Storage & Compute: The 1st piece of the puzzle was to separate storage from compute. This simple concept created a number of distinct advantages. No more “expensive 24×7 appliances” which require large up-front commitments to meet peak processing requirements. Now, you can scale automatically or as required for different workloads and not worry about concurrency/contention/down time. “Pay by the second” usage means your costs are optimised to exactly what you need. Cheap storage (e.g. AWS S3, Azure Blob, GCP Cloud Storage) is leveraged to also minimise your costs. Separate compute also removes the need to provision separate dev/test environments.
Native SQL: The 2nd piece was to use the de-facto data warehousing language (SQL). This makes Snowflake instantly accessible to most of the major toolsets in use today and a distinct advantage over proprietary mechanisms or other approaches like the Hadoop ecosystem (eg. Map/Reduce). The ready availability of SQL skills means minimal time to onboard new people. New data types have been introduced to make semi-structured data like JSON, Parquet, etc also accessible via simple SQL statements. This is quite a powerful concept for today’s IoT use cases which often feature streaming JSON/Parquet/XML formats. Format changes (eg.new columns) are also handled “gracefully” so that your data pipelines don’t break.
Zero Management: As a fully managed SaaS and some intelligent data profiling/indexing on data ingestion, they’ve removed the need for specialised DBAs and people trying to tune complex query plans. That allows you to get on with the data warehousing and not worry about all that admin overhead.
Time Travel (DRP): This is my personal favourite. Anybody who’s done data warehousing in anger will know the sinking feeling of having just committed the “drop table” command on the production database. Because all data changes in Snowflake are effectively logged as SCD-2’s (i.e. logical deletes, not physical deletes), it is child’s play to type in the “undrop table” command and see all your wonderfully restored data on the executive dashboard before anybody has even noticed. This convenient feature makes it also very easy to take snapshots in time for whatever reason you have with minimal storage overheads. A copy is just a copy of the pointers to the production data (i.e. metadata (not data) is replicated). The most common usage is production snapshots for load/performance testing – just take a copy, do your test, delete the copy.
As with any good product, new features are being added to Snowflake all the time. A recent example is sharing data with other Snowflake users via the Time Travel mechanism which negates the need to replicate the data. Add this to the recent Snowflake on Azure and Google GCP and you have the capability to implement a multi-vendor cloud strategy with data redundancy (via data sharing) to your data lake/warehouse/hub as well.
All of the above, add to a compelling argument as to, why would you continue data warehousing on outdated, expensive and hard to maintain OLTP architectures when you could be out there adding business value today and into the future on purpose built, native cloud OLAP architecture.