Reports of the star schema’s death are greatly exaggerated – Part 2
![]() 12 minute read
12 minute read
22 November 2023
Dimensional Modelling in all its forms
This two-part blog series set out to answer a simple question: with all the technological change that has taken place in the Data & Analytics landscape over the past ten years, is Dimensional Modelling still relevant? And, if not, what are the alternatives?
In Part 1 we examined why Dimensional Modelling was created and why it’s persisted for so long. In Part 2 we’ll build on that knowledge to understand how the Star Schema, Dimensional Modelling, and The Kimball Method do (or don’t) differ, and understand more about alternative approaches.
The Kimball Method
The Kimball Group were Data Warehousing thought leaders that published several important books including The Data Warehouse Toolkit (1996, with further revisions in 2007 and 2013). The group closed its doors in 2015 but its works continue to be highly influential within the Data & Analytics community, and some former Kimball Group members still practice as independent consultants. In Toolkit, they detail their approach to Dimensional Modelling, known as the Kimball Method.

Figure 1: The Kimball Group produced several go-to data warehousing references, the most important being The Data Warehouse Toolkit – their complete guide to Dimensional Modelling.
Toolkit contains very nearly everything worth knowing about Dimensional Modelling and is much more than a technical guide. I like to think of the content and methods described in Toolkit as belonging to three broad categories:
- Modelling techniques: used to create performant and user-friendly data models.
- Architecture: providing an overall structure and strategy for the Data Warehouse.
- Business analysis and communication techniques that facilitate (1) and (2).
During the time of Toolkit’s immense popularity and influence, other approaches to Data Warehousing such as Bill Inmon’s Corporate Information Factory (CIF) and – later – Data Vault, utilised Star Schemas as the recommended way to deliver analytical data to end users, and these approaches would agree with much of the Toolkit contents. That is: they intend to present data through integrated data models using terms that the business understands; they structure the data warehouse around clusters of similar datasets (Subject Areas); and they allow transactional data to be sliced and diced through dimensional analysis. So, proponents of all approaches tend to agree on: 1) Modelling techniques.
Where the ideologies diverge is: 2) Architecture. Specifically, whether the presentation layer should be a Conformed Dimensional Model, or independent Data Marts created on a use-case by use-case basis; and whether to use a guiding blueprint for future development like Kimball’s Bus Matrix, or to deliver it all at once in a “big bang”.
Conformed dimensions, as advocated by the Kimball Group, imply that if a Customer makes a purchase in the Sales subject area, then an order is generated for that Customer in the Fulfilment subject area, and finally the Customer submits a warranty claim in the Returns subject area, it’s the same Customer in each case. The customer will have the same attributes across all three subject areas, and to join data from one subject area to another it is the conformed dimensions that assist (in the Kimball Method, fact tables are never joined directly).
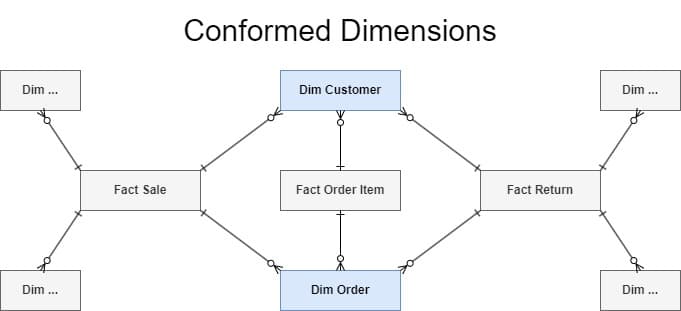
Figure 2: The dimensions Customer and Order are shared by three different fact tables. The Kimball Method describes these dimensions as Conformed, since they are compatible across any records involving Customer and Order.
Conforming dimensions facilitates cross-departmental queries and contributes to a single version of the truth. If instead the Sales, Orders, and Returns Star Schemas from Figure 2 were all independent, with separate versions of Customer, stakeholders using the Star Schemas independently could come to three different conclusions when reconciling the data – for instance, when counting total Customers, or apportioning them to a specific geography – with each conclusion being correct in a specific context but still in conflict with one another. That is, they would have found multiple versions of the truth.
The Kimball architecture approach, through the Bus Matrix, facilitates an iterative way to build out the Enterprise Data Warehouse – developing it one Subject Area at a time, according to priority, until all stakeholders within the business are catered for (each Subject Area is represented by a row in the Bus Matrix, which you might remember from Part 1 of this blog). This incremental approach is also known as the bottom-up approach, which is contrasted by a top-down (or “big bang”) approach, where the entire system is designed and developed before the first users receive anything of value. Assuming we know exactly what we want for the entire organisation a long time in advance (a stretch to say the least!), and that there are no changes throughout delivery, the top-down approach will yield the most efficient delivery of the data warehouse since re-work and technical debt will never occur. However, given the longer implementation time of the top-down approach, it’s possible enterprise systems will change over time, creating unavoidable changes to the downstream data warehouse, and even if priorities don’t change throughout delivery, the bottom-up approach provides immediate value to stakeholders by delivering one subject-area at a time, and gives decision-makers the option to pivot if needed.
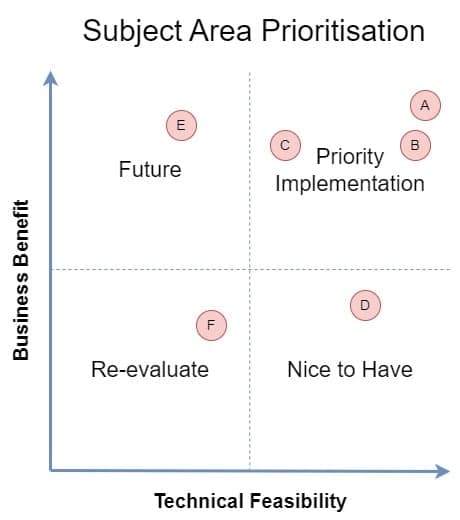
Figure 3: In the Kimball Method, logical groups of datasets and their associated dimensions, called Subject Areas, are ranked on priority considering Technical Feasibility (Do we have the data? Is the data of good quality? Do we have the resources from that business area ready to assist?) and Business Value (What new abilities would access to this data grant us? To what degree would those new abilities benefit the business?). This diagram shows the priorities of six subject areas (arbitrarily labelled A-F), as scored by the project’s Steering Group.
So, proponents of different approaches don’t agree on 2) Architecture, and instead propose alternative architectures, typically with a normalised layer that itself would be considered the Data Warehouse, and with independent Data Marts (Star Schemas that don’t conform to one another) created for each new use-case.
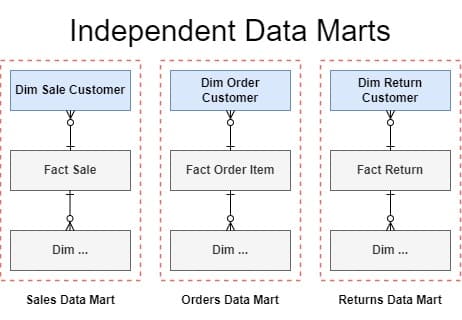
Figure 4: Instead of a conformed Customer dimension, this example shows the Sales, Fulfilment, and Returns Subject Areas, each with their own version of Customer. Because they are not fully compatible with each other, these Star Schemas are referred to as Independent Data Marts.
The Kimball Method… and Other Methods?
Remembering that Dimensional Modelling is all about the presentation of data, it should come as no surprise that the Kimball Group doesn’t care too much about what happens before data is presented. Should it be normalised into an enterprise data model? The Kimball Group thinks it’s not necessary but notes that such normalised models can easily be combined with Dimensional Modelling. When these methods are combined, the architects can choose to use Conformed Dimensions or siloed Data Marts for each use-case (for instance, it’s common for Data Vault data warehouses to use a conformed, Kimball-style dimensional layer, even though the original thought-leadership of that approach called for siloed data marts).
Figure 5: Typical layers in a Data Warehouse architecture. Of these, the Kimball Method pertains only to the Presentation Layer, where users get their data. Sometimes this layer is called the Data Warehouse or Enterprise Data Warehouse, but some methodologies apply that label to a normalised layer prior to presentation.
So as far as Dimensional Modelling is concerned, the most popular alternative modern approach – Data Vault – is essentially no different when we consider that end result to be the presentation layer. But what other approaches are there? Relatively few. Other approaches to data modelling might suit data storage and access for specific use-cases, but don’t do nearly as well as Dimensional Modelling for answering analytical questions; and while other experts have weighed in with tweaks to The Kimball Method (Lawrence Corr and Christopher Adamson are two such examples), their approaches are too similar to the source material to warrant a new category.
One Big Taboo
There is, however, another pseudo modelling approach to consider: One Big Table. How would this approach typically work? Let’s say you already have all the requirements, business rules, and other information you need to develop a data warehouse. You could go right ahead and create a dimensionally modelled Subject Area – a fact table with its surrounding dimensions – but what if instead, you just put your entire result set into one very wide table (i.e., into One Big Table, or “OBT”)? Then you could present that wide table to users. After all, it looks just like an Excel tab, which all our users are familiar with.
In fact, while OBT is seen as new, it is conceptually no different to a siloed Star Schema where all the facts and dimensions are joined up into a single query.
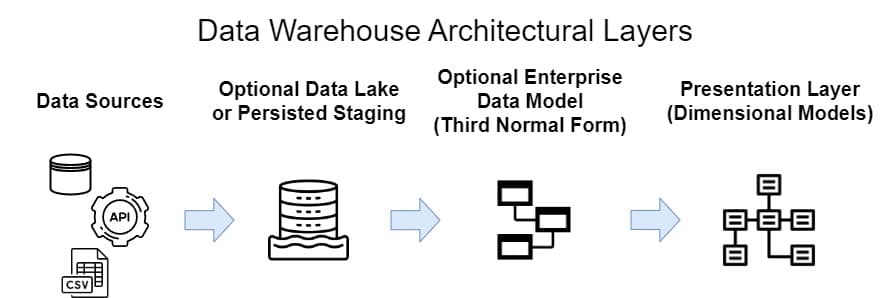
Figure 6: It’s easily possible to convert a well-formed Star Schema into a One Big Table model if your technology stack necessitates such a compromise, but for most use-cases it’s not necessary and will come with a variety of risks.
Proponents of OBT say that it performs better than a Star Schema for certain types of technologies – which it does – but they may fail to mention that it performs far worse for others. One of the reasons for using Dimensional Modelling is performance, but that is not to say it is the most performant way to store data on disk or in memory for all technologies. Indeed, the very reason Dimensional Modelling is faster than normalised models – less joins – is the same reason that OBT can be faster than Dimensional Modelling for certain use cases since OBT has no joins at all!
It’s entirely possible to take a Star Schema and turn it into OBT, and if you are technologically limited by performance, probably by many billions of rows, then by all means, present – as a last step – the data as OBT. After all, the effort to create this “view” of the data, expressed as a percentage of the total project effort and rounded to a whole number, is zero. But creating a OBT view of your data does not mean you no longer have dimensions and facts; rather, it means your dimension and fact relationships are now implicitly baked into a single view of the data, making it less re-usable across different areas of the business and possibly inconsistent when compared to other OBT datasets.
Some OBT implementations are likely well thought-out and appropriate for their stakeholders and use-cases, but oftentimes OBT is used not as a final presentation piece but instead to avoid thinking too much about what we are really delivering to the stakeholders. That’s the topic of the next section.
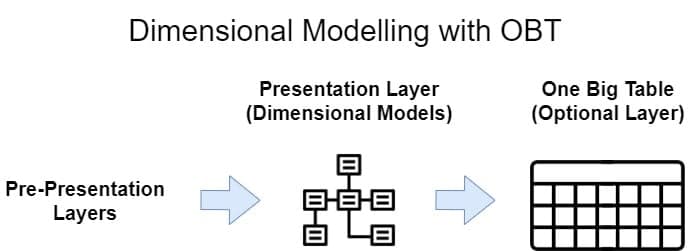
Standard approach? Why bother?
We’ve already talked about 1) Modelling techniques and 2) Architecture, but a crucial element of The Data Warehouse Toolkit is that it provides: 3) Business analysis and communication techniques that facilitate (1) and (2). These are the best practices gleaned from many years of solution delivery, and they will make a successful data platform regardless of the modelling methodology chosen. These learnings are distinctly lacking in teams who choose the obvious other approach: to have no standard approach at all.
Such teams simply make it up as they go and assume that they will make sensible decisions as each new problem arises. This is frequently where organisations start out, and only after certain patterns repeat themselves, usually over many months or years, will they become mature (and frustrated) enough to seek out a more standardised approach (I like to refer to these organisations as future clients).
Since datasets in this approach are delivered to end users as a single table, I’ll continue with the OBT moniker, and the delivery pipeline almost inevitably looks like this:
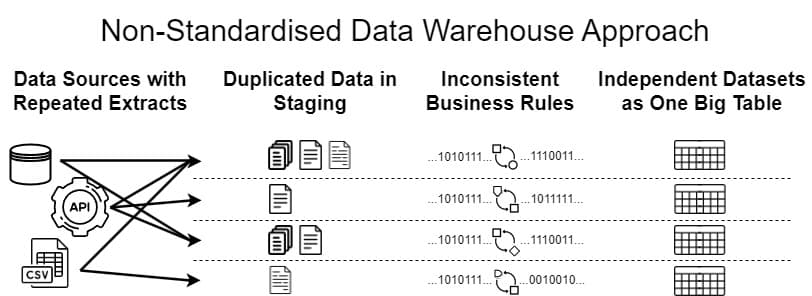
Figure 7: A ‘just get it done’ style approach, typified by inconsistency between different pieces of functionality across the data platform and by varying quality of each release. Though sometimes appropriate as a quick-fix for a single department or use-case, as an enterprise solution this approach will ultimately fall short.
A conformed dimensional model, consisting of many Star Schemas that represent different business processes in action, with the input of many business subject matter experts and stakeholders collaborating with the data teams, provides a thoughtful way to analyse and understand business data. OBT and the “just get it done” approach does not. And if we have many, many OBTs alongside one another then that might come close to a workable solution, but we will have lost a single version of the truth and made something that’s difficult to navigate for users and nigh impossible to maintain.
Rather than putting the business’ fundamental processes into datasets that can be joined by conformed dimensions, non-standard approaches frequently require all the business questions to be known up front. If we create a OBT dataset for sales, how do we answer the question: which of our products have never sold? There’s no row for “not sold” in a sales table, and we don’t have the concept of a product dimension, so it’s a (very basic) question that we can’t answer.
I do think OBTs can exist for certain use-cases; specifically, when all the questions that need to be answered are known in advance, or when it’s necessary for performance or technology reasons. But it’s rare to know all the questions users might want to answer in advance. For a process like Sales, the business might ask:
- What are my Sales by product type (analysed seasonally across all prior periods)?
- How are Sales affected by Promotions (in-store, loyalty programmes, etc.)?
- How do new store Sales affect existing stores in the same geographic region (the same city, the same state or country, etc.)?
- Which products do customers buy together in the same basket? Which products will likely be bought soon after the purchase of some specific product? Which products might our existing customers like to buy?
And there are many more, some of which the users won’t think of until far into the future. If we write the business rules and transformation logic for OBT for each of these, wouldn’t that be a lot more effort than creating a Dimensionally Modelled Sales Subject Area (even if it was virtualised using a semantic layer) and then producing many OBTs from that? I think it would.
Greatly Exaggerated
Bringing us back to this blog’s title reference to Mark Twain’s 1897 witticism, I believe that reports of the Star Schema’s death have been greatly exaggerated.
Since the original creation and popularisation of Dimensional Modelling we’ve seen great advances in the Data & Analytics landscape. We have better analytical tools and data processing technologies, there’s been an explosion in data volume and of unstructured data, and more recently we’ve seen the introduction of AI. While all this means some of the original techniques are not as relevant today as they once were, the core of the approach – thinking in terms of performance metrics and the surrounding descriptive nouns by structuring the data around business process events – is just as relevant as ever.
So, while end users won’t always see the Dimensional Models, it’s always useful to create them – enlarge them and put them on the office wall! – so we can more clearly understand how our businesses operate and how to best serve data to our users.
If your business users could benefit from applying Dimensional Modelling to your Data Platform, Altis are here to help. Contact us today to learn more about our consulting and training services.
Written by
Principal Consultant
Altis Consulting
Related insights
Share
Other insights





Contact us via the form on our website or connect with us on LinkedIn to explore the best solution for your business.