


By Meagan Palmer, Senior Managing Consultant
In today’s landscape, data plays a pivotal role. Success in data initiatives hinges on collaborative teamwork and precise data management. dbt, a leading tool in data operations (data-ops), is at the forefront of instilling robust practices among data-centric teams. Throughout this series, we will delve into the intricacies of a suite of dbt features referred to as dbt Mesh.
First off – what is data mesh and why is everyone talking about it?
Data Mesh is a relatively new concept in the field of data architecture that has gained significant attention in recent times.
Data Mesh is a decentralised approach to data architecture. In this approach, we treat data as a product and the domain or business unit that generates the data are it’s custodians. Data mesh advocates for distributing data ownership and infrastructure responsibilities across different teams or domains within an organisation instead of having it managed by a centralised team.
As you would expect, there are benefits and challenges with this approach.
Possible benefits:
- Scalability: The volume and complexity of your data grows and changes along with the business itself. Data Mesh provides a scalable approach that accommodates growth which can help avoid the bottlenecks typical of traditional centralised approaches. This ensures your data infrastructure remains agile and responsive as your business evolves.
- Empowerment: Allow teams to become self-sufficient in managing their data assets. Have the experts of that domain create data products other domains can leverage.
- Improved time to insight: With data pipelines tailored to specific domains, teams can iterate, experiment, and derive valuable insights by leveraging their expertise.
- Enhanced Data Quality and Governance: Maintaining data quality and governance is no longer a daunting challenge. It is now a process ingrained in the data ecosystem. Individual domains adhere to agreed and robust policies and standards. This fosters trust, compliance, and reliability across the entire data ecosystem. Empowering and equipping data stewards to ensure data remains accurate, reliable, and compliant.
- Alignment with modern technologies & practices: Data mesh enables you to embrace and get the most out of cloud-native architectures, microservices, and DevOps methodologies.
Challenges to be considered:
- Complexity
- Upskilling
- Cultural shift within your organisation, and,
- Technical infrastructure. (dbt can help with this part)
Even if you’re not heading down a data mesh path, you can still implement these dbt features. Doing so can enhance the trust in your data and improve the manageability of your data transformation pipelines.
What is dbt and why is it so loved?
dbt, or Data Build Tool, is a configurable tool that simplifies the data transformation processes. With dbt, you can connect to various databases and write SQL or Python code to create datasets (tables, views, etc) that are then materialised in your database. It is simple to use. You can begin in a lightweight manner and then dive deep into richer functionality. It’s for transformations, testing, documentation, orchestration, and applying data governance. (*Note: Some of these capabilities are in the dbtCloud version only)
Git integration, open-source packages hub, and ability to automate make it a favourite among data engineers and analysts.
Exploring dbt Mesh
dbt Mesh takes collaboration and governance to the next level. It introduces simple mechanisms to allow data owners to manage their data assets. These features are:
- Break up large dbt Projects: Gives you the ability to break large dbt projects into smaller domain-focused projects, while still maintaining dbt lineage across projects.
- Cross Project Referencing: The ability to reference specific models from another dbtCloud project. Enables clean project splits with full cross-project lineage. Boosts governance and flexibility.
- Explorer: Interactive documentation, showing full lineage across all your projects. Zoom in to a specific project or view the project links.
- Model Versions: This is a neatly implemented way to manage breaking changes and deprecate models. It allows downstream users time to adjust.
- Model Contracts: Enforces the agreed data contract and prevents non-compliant data flowing through.
- Groups & Access: Mechanism to control data usage downstream, creating groups with documented owners.
What we’ve seen with our clients
Implementing DBT mesh has become increasingly popular. Altis is working with a number of organisations across several industries in the ANZ region to help them get started on this journey.
Key lessons so far:
- Embrace dbtCloud, especially for Enterprise
We are finding that clients wanting to run a hybrid of dbtCore and dbtCloud miss out on some of the key benefits. The result is time spent finding creative solutions to already solved problems. While it is possible to run both dbt Core and dbt Cloud in a hybrid way, in large enterprises, I would argue that the time and complexity of doing this isn’t worth it.
One of the key reasons for attempting to run both together is that existing dbtCore users do not want to move to a web IDE. These users are comfortable and productive with their development environment. There is now the dbtCloud CLI – this allows these users to use their own local development environment with CLI version of dbt connected to dbt Cloud. - Start with a small number of projects and split them further as required
Our experience so far has led to suggesting an initial central project. Containing the staging and some of the base transformations, which are then referenceable by the domains. Split further as the project and your data mesh implementation matures.
Going for too many project splits early adds complexity before value is seen. - Bring all the users on the journey and have agreed standards upfront
This includes coding conventions, testing, documentation, and security standards. We have worked with several analysts now that feel they are being pulled further into the data pipeline and don’t have the guidance on how to do that. They have the data domain knowledge and skills.
Provide guidance so they can roll into this new way of working effectively.
Let’s dive into how to implement
We will start with adding Model Contracts. Following posts will cover:
- how and why to use model versions
- setting up groups and access control
- pulling it all together with cross project referencing
- viewing end to end lineage with Explorer.
In dbt, the term Model describes a query that is generally materialised in the database as a view or a table. So, Model Contracts are a set list of columns and their data types in each view or table.
Model Contracts are a quick win to introduce without adding any changes to your current flow of data. Having model contracts gives your downstream data users confidence in the data shape. That is, confidence in what columns will be in their data set and what the datatype of those columns will be.
dbt checks that the contract will be upheld BEFORE actually updating the table or view.
If you’re already using dbt
(If you’re new to dbt, jump to getting started tips)
Add Model Contracts to external exposures
Step 1: Identify the table or view that is being referenced downstream. This is often in a ‘presentation’, ‘final’ or ‘marts’ folder.

If you have used Exposures in to document your downstream data use, you can also use that to find the models to add contracts to.
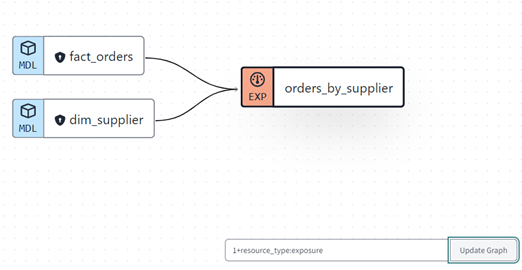
For those that prefer using the command line:
dbt list --select 1+resource_type:exposure
- Step 2: Find that model documentation in a .yml file. If you don’t have one already, create one and add some documentation and tests while you’re going. (the dbt codegen package can help expedite this)
- Step 3: In the .yml configuration, add in the columns and data types and set the contract to enforced.
models:
- name: dim_supplier
config:
contract:
enforced: true
columns:
- name: supplier_sk
data_type: varchar
- name: supplier_key
data_type: number
- name: supplier_name
data_type: varcharSimplified yml to show minimum requirement for a contract. Recommendation is for tests and documentation here as well. This file drives a lot of behaviour.
Reach out if you want to talk about any of the configurations available above.
- Step 4: Add some constraints (Optional). There is some configuration to add constraints to the columns too. Options and enforcement vary depending on your database provider. Tip: remember to use tests if your provider does not support the constraint you want. Constraints will error before the model is built, tests will error after.
- Step 5: Create a Pull Request and arrange to release to production using your usual process.
- Step 6: Repeat for each model that is used externally, for example in PowerBI or by your ML team. If you already have multiple projects, include a contract on any model that you have as a ‘source’ in a different dbt project. This sets a solid foundation for cross-project referencing later.
- Step 7 (optional): When relevant models have a contract, move contract enforcement to the folder level. Use the dbt_project.yml for this config . This will ensure all new presentation models get a contract enforced from the outset.
models:
demo_project:
### other model configs and folders here
presentation:
+materialized: table
+contract:
enforced: true
Snippet of dbt_project.yml showing moving the contract enforcement to a folder called presentation
New to dbt?
Setting up a brand new dbt project or introducing it to your business is a great time to set solid foundations.
Tips for new projects: enable enforced contracts in your presentation layer from the start. As in step six above, add the contract config to your dbt_project.yml. This will ensure that all presentation models have a contract from the get-go.
If you have a multi-project mesh implementation in mind, set the standard of contracts on all public models too. This will facilitate stability and trust in the shape of the data when you start using the cross-project referencing functionality.
Keep your eyes out for a future how-to on cross-project referencing and how to choose where the barrier between projects should be.
What are the benefits of having model contracts?
Benefit 1: There is value in finding out first that there is an issue, especially in Prod. Having a contract failure means you are finding out early that there is an issue. You can take steps to resolve and kick off the correct notifications. Users finding out first and needing to log a ticket erodes trust in both the data and the teams involved.
Benefit 2: Save time on identifying the issue and testing.
This is true with issues that pop-up in production or during development.
The error dbt provides are specific. Troubleshooting can start knowing exactly which column there is an issue with.
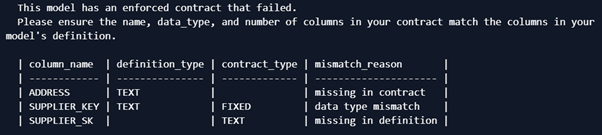
Fast issue identification means more time resolving the issue and preventing future recurrence. The below errors are telling me:
- Address is in the dataset but has not been defined in the contract. The downstream users are not expecting that column.
- Supplier_key is coming through as text in the dataset, but the contract is expecting an integer. Incorrect data types can cause all kinds of issues downstream.
- Supplier_SK is in the contract, but not in the dataset. The downstream users are expecting this column and it’s not there.
Benefit 3: In the event that it is a request for change that causes this contract to fail, this will be identified during development (rather than testing). The developer can identify independently that this is a breaking change. The downstream users won’t be asked to test until a solution can be found. Tip: one of the possible solutions here is using Model Versions to allow time for the downstream users to adapt to the change. More on that in a future post.
About the Author
Meagan is a Senior Managing Consultant with Altis Consulting based in Sydney. She is a dbt Certified Developer and regularly conducts training on dbtCloud.
Connect with Meagan via LinkedIn or get in touch meaganp@altis.com.au
Do you want to find out more about dbt Mesh can enhance your data projects?
Connect with Altis today to discuss how the dbt features can benefit your organisation.